All Posts
Building a RAG Pipeline for the Entire Python Ecosystem
By Andrew Zhou, Nicolas Ouporov

Published November 17, 2023
This blog is a technical deep dive into Context, an open-source experiment from Fleet AI to give LLMs real-time knowledge of coding libraries.
Overview
Why do we care about docs?
LLMs are missing important context.
The world moves fast and libraries are updated all the time. While tools like ChatGPT and Github Copilot have achieved massive adoption amongst developers, their knowledge is incomplete and cutoff at the last training date. If you need help with the latest version of any recently updated library you are pretty much out of luck.
Even ChatGPT fails when asked about its own API changes, giving a deprecated function "openai.ChatCompletion.create()" when asked how to call their endpoint in python.
LLMs lack of real-time knowledge is also a pain for library maintainers. For the Pydantic team, version 2 of their library was released in June 2023, beyond the training cutoff for most LLMs. If you ask chatGPT about pydantic, it has no knowledge of the new changes.
When speaking to the Langchain team, we found that most LLMs know exceptionally little about the library, which can significantly impact adoption in a world where more and more developers rely on coding assistants.
Library Docs are great for CodeGen
Motivated by results from DocPrompter (Zhou, Alon, et al.), we adopted the intuition that retrieving documentation significantly improves code generation. We apply these ideas to the entire python ecosystem, so we chose to build a massive dataset of text sections from major python library docs that could be fed into an LLM on-demand.
We operated on the assumption that documentation is the most exhaustive guide for most libraries and languages. It’s also semi-structured into sections, classes, functions, etc. which gives us methods to preserve meaning after retrieving text chunks at generation-time. Overall, focusing on a specific datatype like library documentation enabled us to make significant improvements over naive RAG solutions. Here is how we did it.
Data Collection
High-level Approach
- We generate a config with information about the relevant start page (like “/docs”), HTML selectors for the text content, and enrich the config with info about the library name, stable release link, license, number of downloads, etc.
- We find and loop through every page, preserving it’s section structure.
- We store as a tree data-structure with representations for each library, page, and section
- We filter out index pages, lengthly change logs, and other irrelevant information.
Documentation Type
Every documentation page could either be Sphinx documentation (~50% of docs), a Github README (~35%), a PyPI page (~7%), or other documentation pages (~8%).
For documentation like Sphinx, we are able to understand the sections, which enables us to link users to relevant sections, chunk according to well-defined bounds, extract section definitions (classes, functions, etc), and order the processed chunks.
Since the format of the docs we are processing is HTML, we want to preserve the meaning conveyed by styling while keeping the length of the styled representation reasonable, so we convert to all the text to markdown. After retrieval, this enables us to reconstruct the original styling.
Data Cleaning
We found that during retrieval, index pages that defined and linked to a vast array of pages would be frequently retrieved as part of the context — sometimes even before the text that was meant to be retrieved in the first place!
Therefore, we decided to remove index pages from our scraper, defined as pages that are 50% or more links. This was so effective that we added it to Langchain’s ReadTheDocs document loader.
We also decided to skip other pages that were not as relevant including the contributing pages, deprecated pages, 404 pages, release notes, etc.
Chunking
For retrieval we needs to split our text into semantically meaningful chunks and add relevant metadata. Code documentation is particularly sensitive to improper breaks.
High-level approach
- We split each structured section into meaningful chunks, obeying the boundaries set by each section
- We preserved metadata and added new metadata like the ordering of the chunks so that we could rerank retrieved content
- We experimented to find the best chunk size, and build a parallelized pipeline using ray.
Splitting docs
Splitting general guides, documentation, and written pieces was straightforward. We abided by several rules:
The splitter cannot split in the middle of any example code block, unless the example code block gets to becoming too big.
Text sizes can vary in size, but cannot exceed 512 tokens to account for OSS model limits.
We tested a variety of text splitters and found that the NLTK text splitter produced the highest quality chunks while preserving the most amount of information.

NLTK is the best option based on qualitative human review.
There were some cases where the NLTK Text Splitter wouldn’t find punctuation to split by for a variety of reasons (very long bulleted lists, big code blocks, etc), so we fall back to the markdown recursive character text splitter if the NLTK splitter cannot split below 512 tokens.
Handling small chunks
There are cases where sections are small (like <50 characters small) where embedding these sections would create noise and irrelevant information during retrieval step. For these sections, we go one layer up and fetch the parent section to chunk instead so that context is preserved. This is one of the many benefits of retaining the structure of the source text.
Evaluations
Methodology
To build our test set, we randomly sampled 140 libraries (weighted by download) and chose 2 sections from each to produce ~50k candidate chunks. We embed all these chunks, and randomly select 50 to build a test set of [question, answer, source] pairs. We then ran evaluations using a hybrid GPT-4 evaluation with human verification.
We formulated a generation score and a retrieval score to evaluate our responses.
For generation, we score the responses using a GPT-4 model with the following prompt:
Your job is to rate the quality of our generated answer
given a query and a reference answer.
Your score has to be between 0 and 5, where 5 is the best score, and 0 is the worst.
You must return your response in a line with only the score.
Do not return answers in any other format.
On a separate line provide your reasoning for the score as well.
Query: {query}
True answer: {gt_answer}
Generated answer: {generated_answer}
Score:When compared with human review over a few samples, we found the scores were closely aligned.
The generated scores are then normalized to be between 0 to 1.
The retrieval score was formulated to give a full score (1) if the ground truth chunk is retrieved, with a score of 1-(n/k) where n is distance from the top of the retrieved chunks and k is the total number of retrieved chunks. If the ground truth chunk is not present, we formulate the score as (1-(n/k))/2 where n is the distance from the top of the retrieved chunks for the highest chunk with the same section as the ground truth chunk.
Results
We optimized for generation score over retrieval score, and found that a chunk size of character length 400 or 1000 were the most effective.
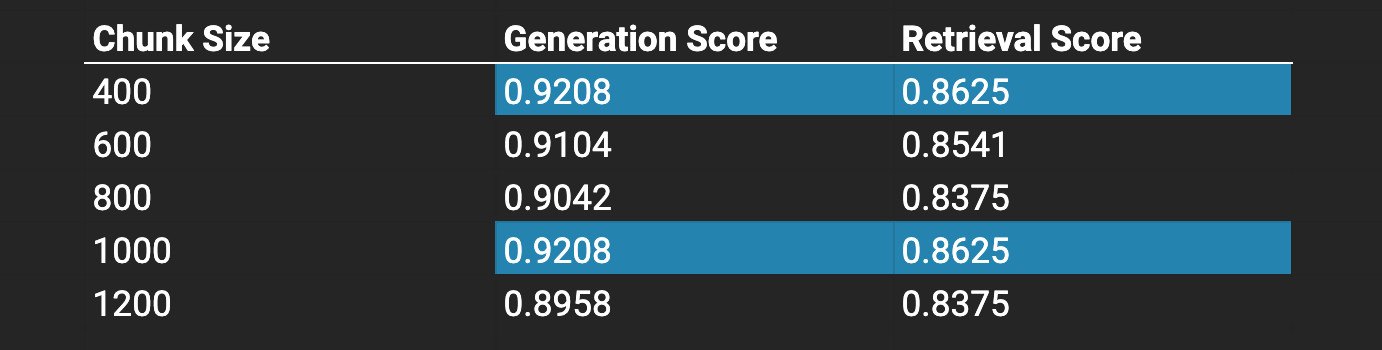
We found that 400 and 1000 are the best chunk sizes.
Embedding
High-level approach
- We evaluated each embeddings model (open & closed source) to pick the right one.
- We evaluated and implemented a hybrid vector search vs a dense vector search.
- We optimized our embeddings pipeline to run efficiently over 4 million chunks.
Model evaluations
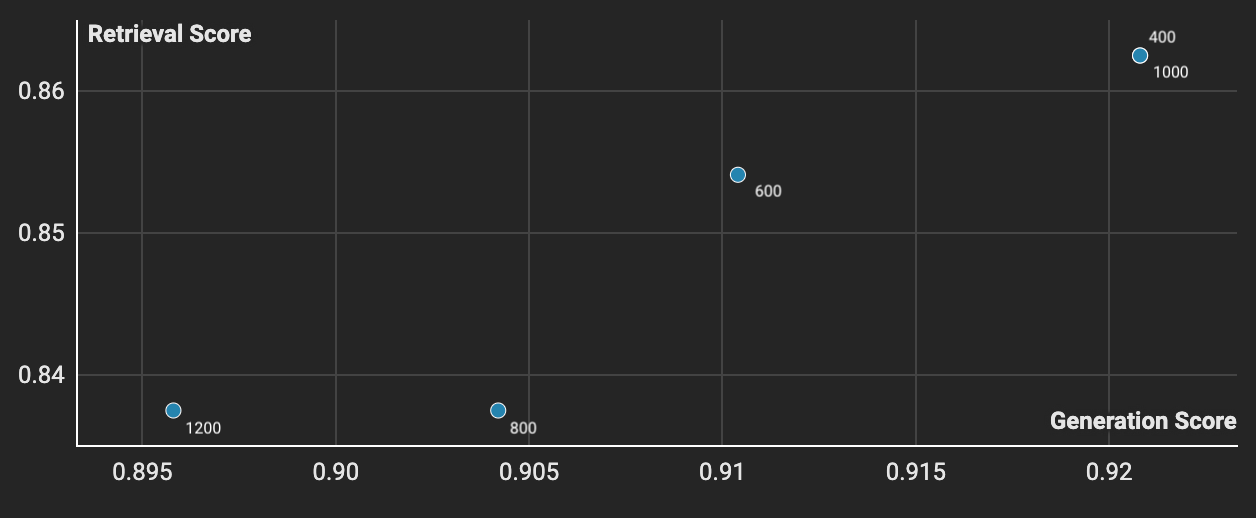
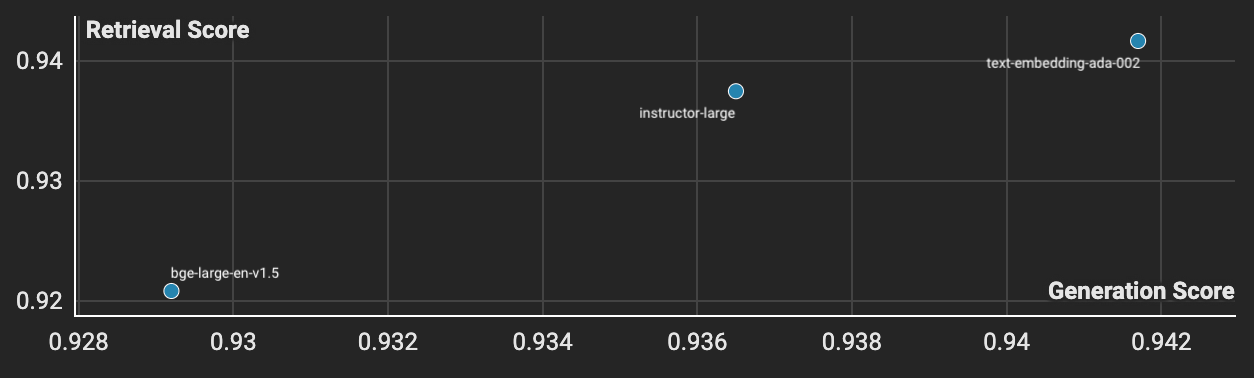
We tested our sampled sections across three embeddings models using the test set of 50 sampled libraries and discovered OpenAI’s text-embedding-ada-002 performed the best for our use case. From a DevX perspective, it’s also much easier to build a retrieval pipeline when you don’t have to host the model that embeds the query. This was top of mind as we wanted people to build useful applications with our embeddings.

text-embedding-ada-002 is the best performing model from our tests.
Sparse Vectors
Evaluations
Hybrid search is a popular vector search practice that has seen a lot of recent traction—is involves searching both sparse vectors (produced by bag-of-words algorithms like BM25) and dense vectors (from embeddings models).
We used BM25 to create our sparse embeddings, fit on a corpus of sample text, which you can find in the google drive.
We wanted to run a set of evaluations to see whether hybrid vector search was useful, and if so, what the balance between sparse / dense (alpha value) should be. The higher the alpha value, the heavier of a weight towards a dense vector search there will be.
From evaluations, we found that the best generation score was given with an alpha of 0.8, while the best retrieval score came from alpha=0.9.
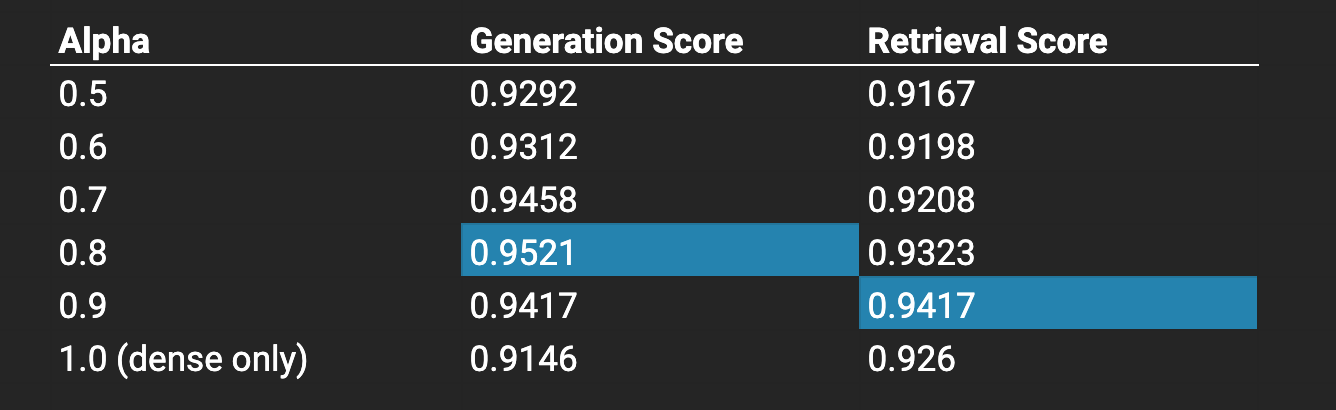
Both the retrieval and generation scores benefit from a higher alpha value.
Embedding
Once we settled on text-embedding-ada-002 as our embeddings model, we started running embeddings through first a batch process that batched our chunks up to the model’s token limit of 8191, then batch embedded it.
Purely basing off rate limits, our theoretical limit would be:

Optimizing the embed job
We opted for a single-thread asyncio implementation so we could optimize for throughput.
We achieved a rate of 1.61 million chunks per hour, which with 4 million chunks was only 2.5 hours! We can attribute the remaining residue time to the time that it takes to batch, encode with tiktoken, compute sparse embeddings, etc. as well as the latency introduced when switching processes within this single-threaded Python function and overhead when starting up this process.
Retrieval
High-level approach
- We evaluated multiple retrieval configurations.
- We implemented these retrieval techniques
Evaluations: k value
We ran evaluations with a varying k values when passing context into the prompt.
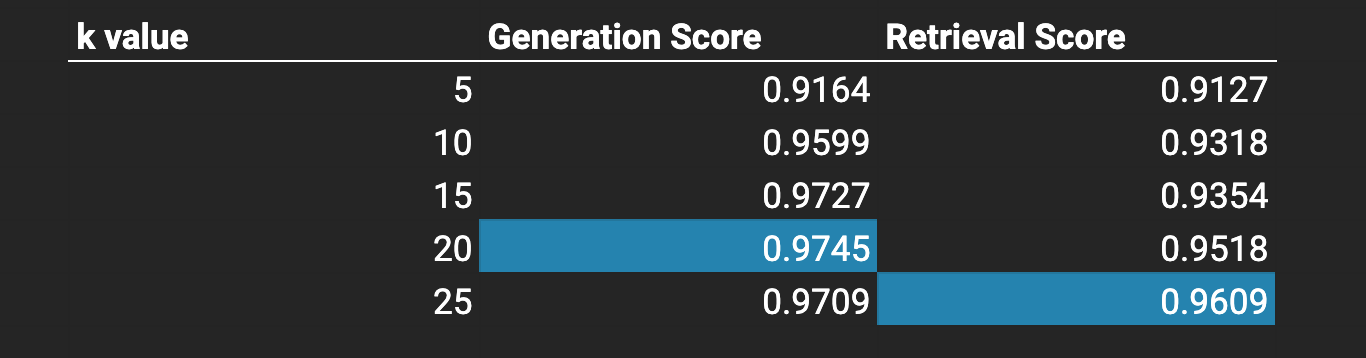
In general, higher k-value perform better.
Surprisingly, a high k value of 20 won out for generation. Upon manual inspection, it looks like it was crucially able to answer a few more questions with low retrieval scores purely based on the sheer amount of context passed in.
Evaluations: reranking
We implemented reranking in two ways:
1. Ordering based on section_index where all items with the same parent would be grouped together and passed into the language model together.
from itertools import groupby
# Group by 'parent' and sort each group by 'section_index'
grouped_contexts = [list(g) for _, g in groupby(contexts, key=lambda x: x['metadata']['parent'])]
sorted_contexts = [sorted(group, key=lambda x: x['metadata']['section_index']) for group in grouped_contexts]
context_text = "\n".join([item["metadata"]["text"] for sublist in sorted_contexts for item in sublist])
2. LLM-based re-ranking where we’d invoke a gpt-4 call to filter out irrelevant pieces of context.
RERANK_PROMPT = """
A list of documents is shown below. Each document has a number next to it along with a summary of the document. A question is also provided.
Respond with the numbers of the documents you should consult to answer the question, in order of relevance, as well
as the relevance score. The relevance score is a number from 1-10 based on how relevant you think the document is to the question.
Do not include any documents that are not relevant to the question.
Example format:
Document 0:
<summary of document 1>
Document 1:
<summary of document 2>
...
Document 24:
<summary of document 10>
Question: <question>
Answer:
Doc: 24, Relevance: 7
Doc: 3, Relevance: 4
Doc: 7, Relevance: 3
Let's try this now:
{context_str}
Question: {query_str}
Answer:
"""
def rerank_context(query_str, contexts):
context_str = "\n".join(
[
f"Document {idx}:\n{result['metadata']['text']}"
for idx, result in enumerate(contexts)
]
)
response = (
client.chat.completions.create(
model="gpt-3.5-turbo-16k",
messages=[
{
"role": "user",
"content": RERANK_PROMPT.replace(
"{context_str}", context_str
).replace("{query_str}", query_str),
}
],
temperature=0.0,
)
.choices[0]
.message.content
)
# Parse response
doc_numbers = [int(num) for num in re.findall(r"Doc: (\d+)", response)]
relevance_numbers = [int(num) for num in re.findall(r"Relevance: (\d+)", response)]
reranked_results = []
for doc, relevance in zip(doc_numbers, relevance_numbers):
if relevance > 5:
reranked_results.append(contexts[doc])
return reranked_results
context_text = "\n".join(
[item["metadata"]["text"] for item in rerank_context(query, contexts)]
)
We also run generation evals against multiple k-values, as reranking has the potential to filter out context.

Rerank by ordering & set a reasonably high k-value.
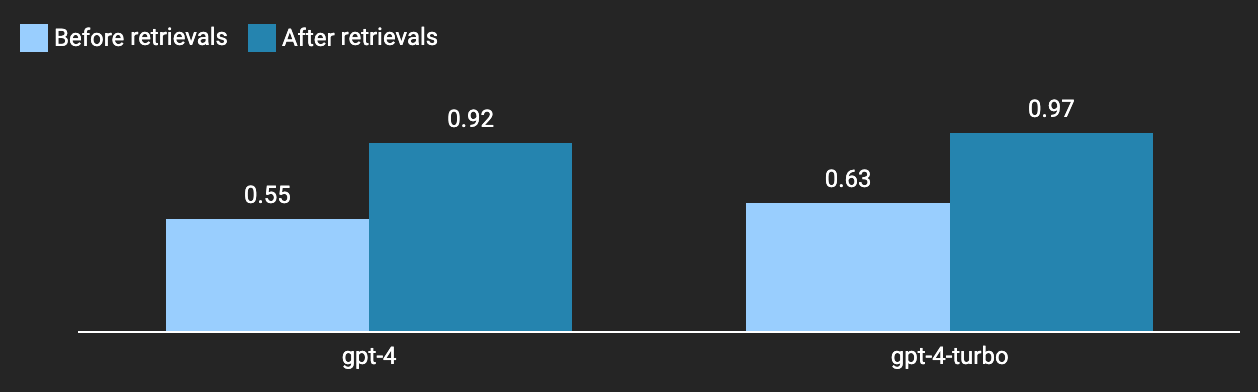
Major Evaluations: Before & After RAG
We evaluated generation scores before and after adding Fleet Context for both gpt-4 and gpt-4-turbo. As expected, there was quite a significant improvement in generation scores.
We attribute this to 1. knowledge of the most recent changes for each library, and 2. relevance of the knowledge.

Success! Library RAG provides meaningful improvements.
Usage
To demonstrate the usefulness of real-time library knowledge and provide an example app for how to use the embeddings, we built a CLI tool that let’s you chat with the dataset. It allows you to filter which libraries you want to consider as well. Instructions below:
pip install fleet-contextcontext --libraries langchain pydantic
To download the embeddings you can go here: https://drive.google.com/drive/u/0/folders/1Gz6lx8dP9QXObQgbMn2AUvalS8s7ExU4
or use our package to download to a df: https://github.com/fleet-ai/context#api
Future Work
The project does not stop here! As some future work, we are considering the following. Reach out to nic@fleet.so if any of these interest you.
- Creating custom versions of library documentation custom made for LLMs. We kept running into this idea of LLMx as a new component of devX since so many developers rely on AI coding assistants. What would documentation look like if it were tailor-made for LLM understanding.
- Finetuning a retrieval model on this task. We feel like significant improvements could be made by finetuning an embeddings model on the task of retrieving information from library docs.
- Building a larger dataset for the Q&A over library docs problem. How can we make our evaluations more robust?
- Embeddings source code, github issues, stack overflow discussion, etc. What other rich content can we add to assist developers.